Современные приложения для синтеза речи значительно отличаются по качеству работы от своих первых аналогов десятилетней давности. Яркий пример тому — программа Балаболка . Данное приложение бесплатное, без каких-либо условий и ограничений. Обладает настолько большими возможностями, что создатели предпочли интегрировать в программу полноценный файл помощи, с подробным описанием всех функций.
Инсталляция и настройка программы балаболка.
Программу проще всего получить непосредственно с сайта разработчика. Там же можно скачать и дополнительное необходимое ПО. Процесс инсталляции незамысловат — приложение копируется в выбранный директорий, системные папки при этом не используются. Интерфейс поддерживает множество языков, в том числе и русский. А вот произношение текста пока будет только на английском. Для использования русского (или любого другого, даже украинского) языка необходимо дополнительно установить компьютерный голос. В сети доступно множество как бесплатных, так и коммерческих голосов. Устанавливаются они довольно просто и быстро.
Вполне может быть, что вам потребуется так же инсталлировать пакет Microsoft Speech Api 4.0
Приложение готово к работе сразу же после запуска. Если установлены бесплатные русские голоса, необходимо выбрать один из них на вкладке SAPI4. Теперь достаточно в окне набрать или вставить текст, и нажать клавишу F5 - начнется чтение вслух текстового фрагмента. Курсор при этом должен находиться в начале текста.
Возможности программы балаболка
Но озвучивание текста — не единственное предназначение программы. Например, с ее помощью можно создавать аудио книги. Произношение любого текста в программе Балаболка можно записать в звуковой файл. Приложение поддерживает следующие форматы: .wav, .mp3, .ogg, .wma, .mp4, .m4a, .m4b, .awb.
Таким образом, нужный вам текст легко преобразовывается в аудиокнигу.
Кстати, программа позволяет автоматически разбивать один большой файл аудиокниги на несколько небольших, в соответствии с выбранными настройками
Настройки сохранения файлов аудиокниг — далеко не единичная опция, доступная пользователю. Кроме этого, можно установить громкость, тембр голоса, скорость произношения. После установки дополнительных (бесплатных) модулей, возможна проверка орфографии; так же пользователь сам может корректировать произношение путем создания собственных «словарей».
В широком смысле - восстановление формы речевого сигнала по его параметрам; в узком смысле - формирование речевого сигнала по печатному тексту.
Синтез речи может потребоваться во всех случаях, когда получателем информации является человек. По тексту или коду сообщения может быть использован в информационно-справочных системах, для помощи слепым и немым, для управления человеком со стороны автомата.
Для выдачи информации о технологических процессах: в военной и авиакосмической технике, в робототехнике, в акустическом диалоге человека с компьютером.
Как звуковой эффект нередко используется в создании электронной музыки.
Все способы синтеза речи можно подразделить на три группы:
параметрический синтез; конкатенативный, или компиляционный (компилятивный) синтез; синтез по правилам.
Параметрический синтез речи является конечной операцией в вокодерных системах, где речевой сигнал представляется набором небольшого числа непрерывно изменяющихся параметров. Параметрический синтез целесообразно применять в тех случаях, когда набор сообщений ограничен и изменяется не слишком часто. Достоинством такого способа является возможность записать речь для любого языка и любого диктора. Качество параметрического синтеза может быть очень высоким (в зависимости от степени сжатия информации в параметрическом представлении). Однако параметрический синтез не может применяться для произвольных, заранее не заданных сообщений.
Компиляционный синтез сводится к составлению сообщения из предварительно записанного словаря исходных элементов синтеза. Размер элементов синтеза не меньше слова. Очевидно, что содержание синтезируемых сообщений фиксируется объёмом словаря. Как правило, число единиц словаря не превышает нескольких сотен слов. Основная проблема в компилятивном синтезе - объёмы памяти для хранения словаря. В этой связи используются разнообразные методы сжатия/кодирования речевого сигнала. Компилятивный синтез имеет широкое практическое применение. За рубежом разнообразные устройства (от военных самолётов до бытовых устройств) оснащаются системами речевого ответа. В нашей стране системы речевого ответа до недавнего времени использовались в основном в области военной техники, сейчас они находят всё большее применение в повседневной жизни, например, в справочных службах операторов сотовой связи при получении информации о состоянии счета абонента.
Полный синтез речи по правилам (или синтез по печатному тексту) обеспечивает управление всеми параметрами речевого сигнала и, таким образом, может генерировать речь по заранее неизвестному тексту. В этом случае параметры, полученные при анализе речевого сигнала, сохраняются в памяти так же, как и правила соединения звуков в слова и фразы. Синтез реализуется путём моделирования речевого тракта, применения аналоговой или цифровой техники. Причём в процессе синтезирования значения параметров и правила соединения фонем вводят последовательно через определённый временной интервал, например 5-10 мс. Метод синтеза речи по печатному тексту (синтез по правилам) базируется на запрограммированном знании акустических и лингвистических ограничений и не использует непосредственно элементов человеческой речи. В системах, основанных на этом способе синтеза, выделяется два подхода. Первый подход направлен на построение модели речепроизводящей системы человека, он известен под названием артикуляторного синтеза. Второй подход - формантный синтез по правилам. Разборчивость и натуральность таких синтезаторов может быть доведена до величин, сравнимых с характеристиками естественной речи.
Синтез речи по правилам с использованием предварительно запомненных отрезков естественного языка - это разновидность синтеза речи по правилам, которая получила распространение в связи с появлением возможностей манипулирования речевым сигналом в оцифрованной форме. В зависимости от размера исходных элементов синтеза выделяются следующие виды синтеза:
микросегментный (микроволновый);
аллофонический;
дифонный;
полуслоговой;
слоговой;
синтез из единиц произвольного размера.
Обычно в качестве таких элементов используются полуслоги - сегменты, содержащие половину согласного и половину примыкающего к нему гласного. При этом можно синтезировать речь по заранее не заданному тексту, но трудно управлять интонационными характеристиками. Качество такого синтеза не соответствует качеству естественной речи, поскольку на границах сшивки дифонов часто возникают искажения. Компиляция речи из заранее записанных словоформ также не решает проблемы высококачественного синтеза произвольных сообщений, поскольку акустические и просодические (длительность и интонация) характеристики слов изменяются в зависимости от типа фразы и места слова во фразе. Это положение не меняется даже при использовании больших объёмов памяти для хранения словоформ.
У синтеза речи долгая история, обросшая легендами. Ещё в Х веке Герберту Аврилакскому приписывали владение искусством изготовления терафима - говорящей мёртвой головы. Сделанная из бронзы, эта голова словами «да» и «нет» отвечала на вопросы любого к ней обращавшегося. В середине XIII века монах-доминиканец Альберт фон Больштедт и английский философ и естествоиспытатель Роджер Бэкон также пытались создавать первые образцы «говорящих голов».
В конце XVIII века датский учёный Христиан Кратценштейн, действительный член Российской Академии Наук, создал модель речевого тракта человека, способную произносить пять долгих гласных звуков (а, э, и, о, у). Модель представляла собой систему акустических резонаторов различной формы, издававших гласные звуки при помощи вибрирующих язычков, возбуждаемых воздушным потоком. В 1778 австрийский учёный Вольфганг фон Кампелен дополнил модель Кратценштейна моделями языка и губ и представил акустическо-механическую говорящую машину, способную воспроизводить определённые звуки и их комбинации. Шипящие и свистящие выдувались с помощью специального меха с ручным управлением. В 1837 учёный Чарльз Уитстоун (Charles Wheatstone) представил улучшенный вариант машины, способный воспроизводить гласные и большинство согласных звуков. А в 1846 году Джезеф Фабер (Joseph Faber) продемонстрировал свой говорящий орга́н Euphonia, в котором была реализована попытка синтезирования не только речи, но и пения.
В конце XIX века знаменитый учёный Александр Белл создал собственную «говорящую» механическую модель, очень схожую по конструкции с машиной Уитстоуна. С наступлением XX века началась эра электрических машин, и учёные получили возможность использовать генераторы звуковых волн и на их базе строить алгоритмические модели.
В 1930-х годах работник Bell Labs Хомер Дадли (Homer Dudley), работая над проблемой поиска путей для снижения пропускной способности необходимой в телефонии, чтобы увеличить её передающую способность, разрабатывает VOCODER (сокращенно от англ. voice - голос, англ. coder - кодировщик) - управляемый с помощью клавиатуры электронный анализатор и синтезатор речи. Идея Дадли заключалась в том, чтобы проанализировать голосовой сигнал, разобрать его на части и пересинтезировать в менее требовательный к пропускной способности линии. Усовершенствованный вариант вокодера Дадли, VODER, был представлен на Нью-Йоркской Всемирной выставке 1939 года.
Первые синтезаторы речи звучали довольно неестественно, и часто едва можно было разобрать производимые ими фразы. Однако качество синтезированной речи постоянно улучшалось, и речь, генерируемую современными системами синтеза речи, порой не отличить от реальной человеческой речи. Но несмотря на успехи электронных синтезаторов речи, исследования в области создания механических синтезаторов речи по-прежнему ведутся, например, для использования в роботах-гуманоидах.
Первые системы синтеза речи на базе вычислительной техники стали появляться в конце 1950-х годов, а первый синтезатор «текст-в-речь» был создан в 1968 году.
ПО и ОС с поддержкой синтеза речи:
TTS компонента Microsoft Agent, в Microsoft Windows
ОС Android с версии 1.6 стал включать поддержку синтеза речи
Система синтеза речи Festival (использует компилятивные методы синтеза)
AT&T Natural Voices
pVoice (проект языка Perl)
ESpeak (использует формантный синтез)
Gnuspeech - система артикулятивного синтеза
RSS To Speech - приложение и гаджет для Windows, использующий TTS для чтения RSS-каналов
Гаджет Новости Вслух для Google Desktop
Read Words Eng 4 версия Декабрь 2010 г. доступна на tinyurl.com/7uedfb6
17. Физическое моделирование. – это очень сложный вид синтеза, т.к. для имитации даже самых простых инструментов требуются огромные вычислительные методы, где за основу берётся моделирование физических процессов инструмента. Т.е. например при иммитации скрипки будут моделироваться характеристики инструмента определяющие его реальное звучание, такие как: парода дерева, составл лака, геометрические размеры, материал струн, смычка и т.д. Естественно, перевести их в алгоритмы полностью не выйдет ни за что, хотя имеет место приближение (например, алгоритм Карплюса-Стронга для имитации колебания струны), но по идее - такой метод должен давать наиболее точную имитацию акустического инструмента. Весь вопрос - в процессорных мощностях.
Впервые результат физического моделирования нам показал фирма Yamaha, в ряде синтезаторов VL-1 и VL-7
Порой надо озвучить текст, который написан на компьютере. Но как это сделать? Необходимо использовать специальное программное обеспечение, которое называется синтезатором речи. С помощью этой утилиты можно превратить письменный текст в устную речь. На просторах Всемирной паутины существует куча десктопных речевых синтезаторов. Тем не менее лучше использовать онлайн-сервисы. Ведь в таком случае не придется скачивать софт на ПК, засоряя таким образом память. В этой статье мы рассмотрим лучшие онлайн говорилки.
Синтезаторы речи имеют довольно широкий спектр применения. В первую очередь подобные программы будут полезны людям с ограниченным возможностями. К примеру, изначально синтезаторы речи предназначались для людей, которые имеют проблемы со зрением и не могут читать текст с монитора.
Говорилки могут стать хорошим помощником в процессе обучения. К примеру, их можно использовать чтобы слушать иностранную речь и тренировать таким образом восприятие. Также синтезатор речи применяют для того, чтобы слушать книги, занимаясь при этом бытовыми делами.
Лучшие онлайн говорилки
На сегодняшний день веб-говорилки в плане качества воспроизведения ничем не уступают десктопным программам. Интернет-утилиты способны читать с различной скоростью, тембром и пр. Рассмотрим же самые популярные преобразователи текста в речь.
Но для начала стоит подметить, что большинство онлайн синтезаторов речи ограничивают возможность бесплатного воспроизведения. Веб-утилиты дают прослушать пару сотен символов, чтобы пользователь смог оценить качество сервиса. За полный функционал придется заплатить определенную сумму.
Acapela
Acapela – это один из самых популярных речевых синтезаторов. Веб-утилита поддерживает более 30 языков. Одно из главных достоинств этого интернет-ресурса – огромное количество голосов. Для того же английского доступно около 20 тембров (женщина, мужчина, ребенок, подросток, радостный и пр.). К сожалению, российский язык обделили. Для воспроизведения текста на русском доступен лишь один женский голос.
Веб-программа имеет минимальное количество настроек. Благодаря этому разобраться с управлением сможет любой. Чтобы воспроизвести текст надо всего лишь:
- Кликнуть на первое поле. Появится список, в котором необходимо выбрать язык воспроизведения.
- Нажмите на следующее поле. В списке нужно выбрать один из предложенных тембров.
- В большое поле введите текст, который необходимо превратить в аудио дорожку.
- Затем надо согласиться с правилами сервиса. Чтобы сделать это, ставим галочку напротив соответствующего пункта. Появится кнопка Listen, нажав на которую можно прослушать введенный ранее текст.
Звучание у веб-программы вполне достойное. Максимальное количество символов, которые можно озвучить – 300.
Linguatec
Также стоит обратить свое внимание на сервис под названием Linguatec . Это немецкий интернет-ресурс, который пользуется огромной популярностью и за пределами родины. И это вовсе не удивительно. Веб-сервис поддерживает более чем 40 языков (само собой, в их число входит и русский). Что интересно, Linguatec способен воспроизводит различные диалекты. К примеру, имеется несколько версий английского: британский, американский, австралийский, ирландский и пр. Благодаря этой функции Linguatec – это отличная программа для тех, кто хочет узнать правильное произношение того или иного слова на иностранном языке.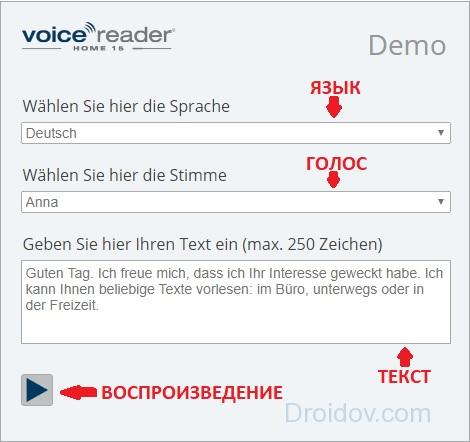
Текст можно воспроизводить как мужским, так и женским голосом. Лимит бесплатного воспроизведения составляет 250 символов. Чтобы получить полный функционал, придется приобрести десктопный синтезатор речи. Его стоимость составляет 30 евро.
Как использовать онлайн синтезатор речи? Необходимо руководствоваться следующей инструкцией:
- Кликните на выпадающий список под надписью Voice Reader и определите язык воспроизведения.
- В выпадающем списке, который расположен немного ниже, определите голос. К примеру, для немецкого языка тут всего несколько вариантов произношения: мужской голос — Yannick и Markus, женский – Petra и Anna.
- Теперь введите текст, который надо воспроизвести, в соответствующее поле. Помните, что его размер не должен превышать 250 знаков (с учетом пробела).
- Чтобы преобразовать символы в аудио, необходимо кликнуть на кнопку со стрелочкой.
Oddcast
Oddcast – это довольно известная компания, которая занимается созданием интерактивных-компаньонов для различных брендов. Также у фирмы имеется свой собственный синтезатор речи, который можно использовать чтобы воспроизвести текст. Веб-утилита поддерживает около 30 языков. Большинство имеют несколько вариаций женского и мужского голоса. Программа способна воспроизвести текст величиной до 170 символов.
Отличительная черта данного сервиса – анимированная модель. Она следит за курсором и во время воспроизведения текста шевелит губами. Модель не несет в себе никакого полезного функционала. Ее цель – продемонстрировать возможности компании Oddcast.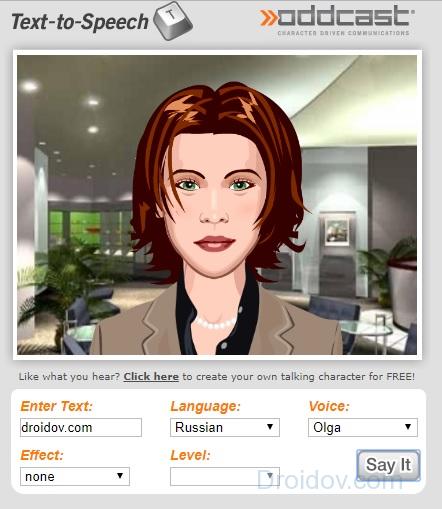
Работать с Oddcast очень просто. Необходимо настроить основные характеристики веб-утилиты. Всего в программе предусмотрено 5 параметров:
- Enter Text. Сюда пишем текст, который необходимо преобразовать в речь.
- Language. Тут надо выбрать язык, на котором текст будет воспроизведен.
- Voice. Выбираем голос для чтения (их количество зависит от выбранного языка).
- Effect. Oddcast позволяет наложить на озвученный текст голосовые эффекты. Выбор довольно велик. Есть функция ускорения, эхо, питча и т.д.
- Level. Позволяет настроить выбранный эффект. К примеру, если вы используете ускорение, то с помощью данного поля вы можете установить насколько быстро текст будет воспроизводиться.
Изменив характеристики под свои потребности, можете запустить говорилку. Для этого необходимо кликнуть на кнопку Say it.
iSpeech
Еще один сервис, на который стоит обратить свое внимание – iSpeech . Веб-утилита имеет хороший голосовой движок, что положительным образом сказывается на качестве аудио. Сервис поддерживает около 30 языков. Максимальное количество символов, которые можно озвучить – 150.
Интерфейс сервиса выполнен в минималистичном стиле. Все сделано очень наглядно. Чтобы выбрать язык, кликаем на соответствующий флаг. Если надо определить тембр, кликаем на женскую или мужскую иконку. Кроме этого, программа имеет три режима воспроизведения. Можно прослушать текст в медленном, нормальном или же ускоренном темпе. Установив нужные параметры, надо кликнуть на кнопку Play. Начнется преобразование текста в устную речь.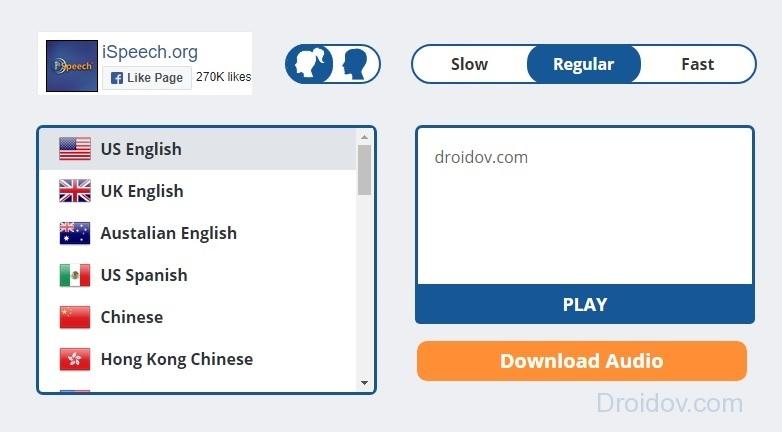
iSpeech идеально подойдет для изучения иностранного. Во время воспроизведения утилита подсвечивает слова, которые были произнесены вслух. Благодаря этому можно узнать правильное звучание конкретного слова, не отвлекаясь при этом от темы текста. Еще одна особенность сервиса заключается в том, что озвученный фрагмент можно скачать на свой ПК в виде аудио дорожки. Тем не менее эта услуга доступна только владельцам платных аккаунтов, стоимость которых довольно высока. Самая дешевая подписка обойдется в 500 долларов.
Text-To-Speech
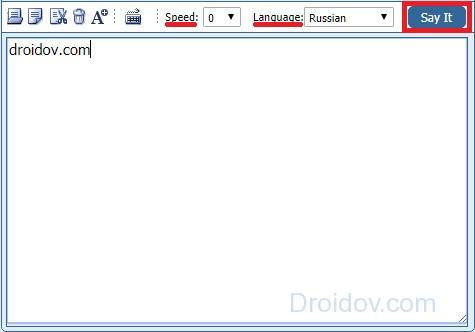
Text-To-Speech – синтезатор речи, который может похвастаться хорошим голосовым движком. Интернет-утилита обладает очень простым, незамысловатым интерфейсом. Программа поддерживает около 10 самых популярных языков. Само собой, в их число входит и русский. Чтобы работать с этим веб-ресурсом достаточно:
- Выбрать параметры для озвучивания текста. Всего их два. Чтобы выбрать язык надо кликнуть на выпадающий список около надписи Language. Рядом можно заметить параметр Speed. Он отвечает за скорость чтения и устанавливается аналогичным образом.
- Теперь надо ввести текст в соответствующее поле. Веб-утилита способна обрабатывать фрагменты, размер которых не превышает 1000 символов.
- Далее необходимо кликнуть на кнопку Say it. Программа выдаст аудиофайл с вашим текстом. Прослушать его можно прямо на сайте.
Google Переводчик
Веб-сервис под названием Google Переводчик включает в себя говорилку. Пользоваться ей очень просто. Необходимо ввести текст в соответствующее поле и кликнуть на иконку динамика. Вуаля – робот прочитал указанный фрагмент. Google Переводчик имеет лимит на величину текста. Нельзя вводить больше 5000 символов.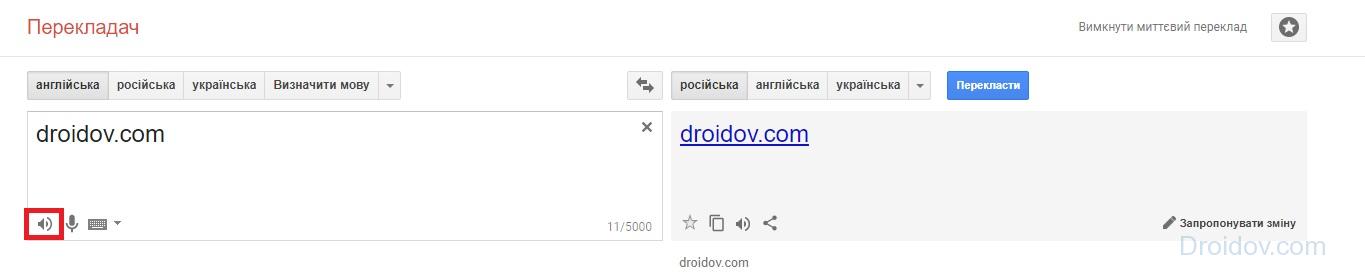
Главное достоинство программы Google Переводчик заключается в том, что она поддерживает огромное количество языков. Тем не менее не обошлось и без ложки дегтя. Во-первых, нельзя изменить тембр голоса, скорость чтения и прочие параметры. Во-вторых, качество воспроизведение оставляет желать лучшего.
From-Text-To-Speech
Большой объем текста позволяет обработать веб-сервис под названием From-Text-To-Speech . Утилита способна конвертировать до 50 тысяч символов за раз. Это на порядок выше чем у конкурентов. Веб-программа поддерживает 10 языков, которые пользуются наибольшей популярностью. В их число входит и русский.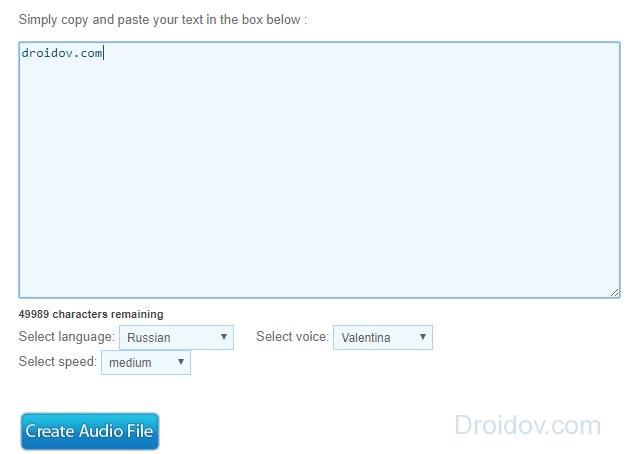
Чтобы воспользоваться веб-сервисом для начала надо настроить параметры озвучки. Благо их тут не так много. В первую очередь надо выставить язык и определить голос, который будет читать текст. Для русского доступен лишь один тембр – женский. Затем надо настроить скорость чтения. Всего есть четыре варианта: медленный, нормальный, быстрый и очень быстрый. Выставив подходящие параметры необходимо кликнуть на кнопку Create Audio File.
Начнется процесс конвертации. Как правило, это занимает не больше минуты. По окончании превращения произойдет переход на новую страницу. Там будет гиперссылка в виде надписи Download audio file. Надо кликнуть на нее ПКМ и в выпадающем списке выбрать вариант «Сохранить ссылку как». Выбирайте место на своем ПК и загружайте аудио. Файл сохраняется в формате MP3.
2уха
Нельзя не отметить отечественные сервисы для преобразования текста в аудио. Одним из лучших в этом деле является веб-сайт под названием 2уха . Главное достоинство сервиса – возможность работать с большими объемами текста. Если другие ресурсы озвучивают небольшие фрагменты до 200-300 знаков, то 2уха способен обработать 100 КБ текста. Это около 100 тысяч символов. И, что самое главное, все совершенно бесплатно.
Как же работать с сайтом 2уха? Все очень просто. Чтобы конвертировать текст в устную речь надо всего лишь:
Данный сервис определенно заслуживает внимания. Качество озвученного текста на вполне достойном уровне. Да и возможность обрабатывать огромные файлы тоже не может не радовать. Однако есть у веб-сервиса 2уха и недостатки. К примеру, количество доступных языков. Сервис работает только с русским.
Вконтакте
Недавно посмотрел новости, передавали что появилась новая программа для перевода текстовой информации в речевую. Называется синтезатор речи или читалка. По телевизору эта программа говорила не хуже человека.
Я решил найти самую последнюю версию похожей программы чтобы проверить её возможности.
Докапаться до правды и узнать насколько далеко шагнуло человечество в создании искусственного интеллекта!
На деле всё было не так просто, как выглядело на тв. Я не буду рассказывать о таких примитивных программах как Горыныч или Говорилка, это пережиток прошлого, и без сурдопереводчика не понять - чем пытается прочитать программа, написанный тобой текст.
Пришлось много разбираться чтобы найти что-то схожее с тв-версией программы. В итоге оказалось что: Программы для синтеза речи состоят из нескольких независимых компонентов. И чтобы компьютер начал читать мой текст, необходимо установить несколько независимых компонентов: Движок программы (Text to Speech/TTS), Синтезатор речи (Для TTS голосовую речь в виде диктора) и оболочку программы - через которую управлять этим (совершенно любую, я пробовал TalkerPro и TextAloud).Более того, эти компоненты находятся в открытом коде, и можно править их самостоятельно, доводя речь диктора до совершенства, и создавая словари для синтезатора.
Я решил опубликовать наиболее достойные разработки синтеза речи. Российские разработчики этим не занимаются, а занимаются лишь крупные иностранные компании. Поэтому русскоязычных программ для превращения текста в речь не много.
В итоге мой взор пал на 3 компании, у которых есть синтезаторы речи и движки. Это:Nuance.com (Речевой синтезатор "Катерина" СканСофт);Также для сравнения я продемонстрирую возможности устаревшей компании Sakrament.com (Синтезатор "Ольга").
Acapela-group.com (Речевые синтезаторы "Алёна" и "Николай")
и Loquendo.com (голос "Дмитрий" и "Ольга").
Компания Acapela-group.com
Голос "Алёна"
Это самый последний синтезатор искусственной речи, который я смог найти в интернете. Дата создания: конец 2008г для "Алёны". Правда у меня возникли большие трудности в установке этой программы на компьютер. На сайте компании есть он-лайн синтезатор , где можно протестировать его. Но чтобы установить его у себя, потребуется установить TTS Infovox Desktop 2.2, который отказался у меня устанавливаться. И пришлось его искать на других пиратских сайтах. Сам синтезатор речи "Алёна" занимает 150Мб до установки!
Частота звука у синтезатора "Алёна" 22Khz (2008г), а у синтезатора "Николай" 16Khz (2005г). Это заметная разница при прослушивании. После установки, появляется собственная оболочка для работы с диктором, называется SpeechPad - работает только с "Алёной". "Николай" можно скачать в полном архиве всех синтезаторов, внизу темы. На сайте Акапелла, его не найти.
Компания Nuance.com СканСофт
Голос "Катерина"
На сайте компании, также имеется онлайн синтезатор , где можно протестировать его самостоятельно. Правда там находится другой голос - Милена (скачать можно отсюда - http://mytts.forum2x2.r...). И сам синтезатор переименован теперь в Vocalizer5, всё же движок не изменился, читает не лучше Катерины. Дата: около 2008 года, хотя не уверен. С самой программой трудностей у меня не возникло, необходимо было установить лишь сам синтезатор речи "Катерина" и она заработала во всех голосовых читалках. Также нашёл ещё один синтезатор "Катерина 2" - читает не плохо, но почему то чувство что обкурилась баба, смеялся до слёз. Данный синтезатор отличается от синтезатора в архиве внизу темы.
Голос "катерина 2"
Компания Loquendo
Синтезатор "Ольга"
Синтезатор "Дмитрий" лишь демо.
На сайте есть онлайн синтезатор , правда у меня отказался работать. Синтезаторы работают на частоте 32Khz. Сам движок от компании Loquendo и синтезатор "Ольга" появились давно, около 2008 года. А "Дмитрий" гораздо позже, в середине 2009 года, поэтому это самый последний синтезатор речи, который я смог найти. Установка не трудная, скачать движок и голос "Ольга" можно После установки, появляется собственная программная оболочка для работы с голосом, называется Loquendo TTS 7 Director. Синтезатор "Дмитрия" я так и не смог найти, возможно это его голос и звучал по тв. Лицензионная версия стоит огромных денег, поэтому буду ждать когда хакеры опубликуют его движок в открытом месте.
Компания Sakrament.com
Голос "Ольга"
Эта версия программы прошлого поколения, демонстрирую для смеха, версия 2000-х годов. Трудности в установки нет. На сайте онлайн копии нет. Больше всего потребовалось устанавливать дополнительных программ и отдельных движков, чтобы она заработала.
Увы, более стоящего я найти не смог, возможно плохо искал, хотя потратил много времени. Ходил по небезопасным сайтам, где было много вирусов. Поэтому не советую повторять мои подвиги без антивируса. Архив со всеми программами для речи, находится ниже.Заметил особенность: В зависимости от программы оболочки, в которой вводится текст - произношение дикторов меняется. Не стоит устанавливать все движки и синтезаторы сразу. Кто знает что-то лучшее в достижении науки - пишите ниже.
Подробнее узнать о речевых движках или голосовых синтезаторах - или или
Добавлено 30 мая:
Уже после написания темы я наконец нашёл тот речевой движок, о котором говорилось по тв. Это сайт ЦРТ - центр реч. технологий. Онлайн демо синтезатора Vital Voice . Петербургская разработка.
[ссылка] Архив со всеми программами и инструкциями (кроме Дмитрия Локвендо и Владимира ЦРТ), 400МбБыстрое
технология распознавания речи
Yandex Speechkit Автопоэт .
Подготовка текста
Произношение и интонирование
странице или на специальном ресурсе сайт
Многим из вас наверняка доводилось управлять компьютером или смартфоном с помощью голоса. Когда вы говорите Навигатору «Поехали на Гоголя, 25» или произносите в приложении Яндекс поисковый запрос, технология распознавания речи преобразует ваш голос в текстовую команду. Но есть и обратная задача: превратить текст, который есть в распоряжении компьютера, в голос.
В Яндексе для озвучивания текстов используется технология синтеза речи из комплекса Yandex Speechkit . Она, например, позволяет узнать, как произносятся иностранные слова и фразы в Переводчике. Благодаря синтезу речи собственный голос получил и Автопоэт .
Подготовка текста
Произношение и интонирование
Другими словами, для синтеза каждых 25 миллисекунд речи используется множество данных. Информация о ближайшем окружении обеспечивает плавный переход от фрейма к фрейму и от слога к слогу, а данные о фразе и предложении в целом нужны для создания правильной интонации синтезированной речи.
Чтобы прочитать подготовленный текст, используется акустическая модель. Она отличается от акустической модели, которая применяется при распознавании речи. В случае с распознаванием модели нужно установить соответствие между звуками с определёнными характеристиками и фонемами. В случае с синтезом акустическая модель, должна, наоборот, по описаниям фреймов составить описания звуков.
Откуда акустическая модель знает, как правильно произнести фонему или придать верную интонацию вопросительному предложению? Она учится на текстах и звуковых файлах. Например, в неё можно загрузить аудиокнигу и соответствующий ей текст. Чем больше данных, на которых учится модель, тем лучше её произношение и интонирование.
Подробнее о технологиях из комплекса Yandex SpeechKit можно узнать на этой странице или на специальном ресурсе . Если вы разработчик и хотите протестировать облачную или мобильную версию SpeechKit, вам поможет сайт , посвящённый технологиям Яндекса.
","contentType":"text/html"},"proposedBody":{"source":"
Многим из вас наверняка доводилось управлять компьютером или смартфоном с помощью голоса. Когда вы говорите Навигатору «Поехали на Гоголя, 25» или произносите в приложении Яндекс поисковый запрос, технология распознавания речи преобразует ваш голос в текстовую команду. Но есть и обратная задача: превратить текст, который есть в распоряжении компьютера, в голос.
Если набор текстов, которые надо озвучить, относительно невелик и в них встречаются одни и те же выражения — как, например, в объявлениях об отправлении и прибытии поездов на вокзале, — достаточно пригласить диктора, записать в студии нужные слова и фразы, а затем собрать из них сообщение. С произвольными текстами, однако, такой подход не работает. Здесь пригодится технология синтеза речи.
В Яндексе для озвучивания текстов используется технология синтеза речи из комплекса Yandex Speechkit . Она, например, позволяет узнать, как произносятся иностранные слова и фразы в Переводчике. Благодаря синтезу речи собственный голос получил и Автопоэт .
Подготовка текста
Задача синтеза речи решается в несколько этапов. Сначала специальный алгоритм подготавливает текст, чтобы роботу было удобно его читать: записывает все числа словами, разворачивает сокращения. Затем текст делится на фразы, то есть на словосочетания с непрерывной интонацией — для этого компьютер ориентируется на знаки препинания и устойчивые конструкции. Для всех слов составляется фонетическая транскрипция.
Чтобы понять, как читать слово и где поставить в нём ударение, робот сначала обращается к классическим, составленным вручную словарям, которые встроены в систему. Если в нужного слова в словаре нет, компьютер строит транскрипцию самостоятельно — опираясь на правила, заимствованные из академических справочников. Наконец, если обычных правил оказывается недостаточно — а такое случается, ведь любой живой язык постоянно меняется, — он использует статистические правила. Если слово встречалось в корпусе тренировочных текстов, система запомнит, на какой слог в нём обычно делали ударение дикторы.
Произношение и интонирование
Когда транскрипция готова, компьютер рассчитывает, как долго будет звучать каждая фонема, то есть сколько в ней фреймов — так называют фрагменты длиной 25 миллисекунд. Затем каждый фрейм описывается по множеству параметров: частью какой фонемы он является и какое место в ней занимает; в какой слог входит эта фонема; если это гласная, то ударная ли она; какое место она занимает в слоге; слог — в слове; слово — в фразе; какие знаки препинания есть до и после этой фразы; какое место фраза занимает в предложении; наконец, какой знак стоит в конце предложения и какова его главная интонация.
Другими словами, для синтеза каждых 25 миллисекунд речи используется множество данных. Информация о ближайшем окружении обеспечивает плавный переход от фрейма к фрейму и от слога к слогу, а данные о фразе и предложении в целом нужны для создания правильной интонации синтезированной речи.
Чтобы прочитать подготовленный текст, используется акустическая модель. Она отличается от акустической модели, которая применяется при распознавании речи. В случае с распознаванием модели нужно установить соответствие между звуками с определёнными характеристиками и фонемами. В случае с синтезом акустическая модель, должна, наоборот, по описаниям фреймов составить описания звуков.
Откуда акустическая модель знает, как правильно произнести фонему или придать верную интонацию вопросительному предложению? Она учится на текстах и звуковых файлах. Например, в неё можно загрузить аудиокнигу и соответствующий ей текст. Чем больше данных, на которых учится модель, тем лучше её произношение и интонирование.
Наконец, о самом голосе. Узнаваемыми наши голоса, в первую очередь, делает тембр, который зависит от особенностей строения органов речевого аппарата у каждого человека. Тембр вашего голоса можно смоделировать, то есть описать его характеристики — для этого достаточно начитать в студии небольшой корпус текстов. После этого данные о вашем тембре можно использовать при синтезе речи на любом языке, даже таком, которого вы не знаете. Когда роботу нужно что-то сказать вам, он использует генератор звуковых волн — вокодер. В него загружается информация о частотных характеристиках фразы, полученная от акустической модели, а также данные о тембре, который придаёт голосу узнаваемую окраску.
В качестве примера мы озвучили два последних предложения предыдущего абзаца разными голосами — мужским и женским:
Подробнее о технологиях из комплекса Yandex SpeechKit можно узнать на этой странице или на специальном ресурсе . Если вы разработчик и хотите протестировать облачную или мобильную версию SpeechKit, вам поможет сайт , посвящённый технологиям Яндекса.
Многим из вас наверняка доводилось управлять компьютером или смартфоном с помощью голоса. Когда вы говорите Навигатору «Поехали на Гоголя, 25» или произносите в приложении Яндекс поисковый запрос, технология распознавания речи преобразует ваш голос в текстовую команду. Но есть и обратная задача: превратить текст, который есть в распоряжении компьютера, в голос.
Если набор текстов, которые надо озвучить, относительно невелик и в них встречаются одни и те же выражения - как, например, в объявлениях об отправлении и прибытии поездов на вокзале, - достаточно пригласить диктора, записать в студии нужные слова и фразы, а затем собрать из них сообщение. С произвольными текстами, однако, такой подход не работает. Здесь пригодится технология синтеза речи.
В Яндексе для озвучивания текстов используется технология синтеза речи из комплекса Yandex Speechkit . Она, например, позволяет узнать, как произносятся иностранные слова и фразы в Переводчике. Благодаря синтезу речи собственный голос получил и Автопоэт .
Подготовка текста
Задача синтеза речи решается в несколько этапов. Сначала специальный алгоритм подготавливает текст, чтобы роботу было удобно его читать: записывает все числа словами, разворачивает сокращения. Затем текст делится на фразы, то есть на словосочетания с непрерывной интонацией - для этого компьютер ориентируется на знаки препинания и устойчивые конструкции. Для всех слов составляется фонетическая транскрипция.
Чтобы понять, как читать слово и где поставить в нём ударение, робот сначала обращается к классическим, составленным вручную словарям, которые встроены в систему. Если в нужного слова в словаре нет, компьютер строит транскрипцию самостоятельно - опираясь на правила, заимствованные из академических справочников. Наконец, если обычных правил оказывается недостаточно - а такое случается, ведь любой живой язык постоянно меняется, - он использует статистические правила. Если слово встречалось в корпусе тренировочных текстов, система запомнит, на какой слог в нём обычно делали ударение дикторы.
Произношение и интонирование
Когда транскрипция готова, компьютер рассчитывает, как долго будет звучать каждая фонема, то есть сколько в ней фреймов - так называют фрагменты длиной 25 миллисекунд. Затем каждый фрейм описывается по множеству параметров: частью какой фонемы он является и какое место в ней занимает; в какой слог входит эта фонема; если это гласная, то ударная ли она; какое место она занимает в слоге; слог - в слове; слово - в фразе; какие знаки препинания есть до и после этой фразы; какое место фраза занимает в предложении; наконец, какой знак стоит в конце предложения и какова его главная интонация.
Другими словами, для синтеза каждых 25 миллисекунд речи используется множество данных. Информация о ближайшем окружении обеспечивает плавный переход от фрейма к фрейму и от слога к слогу, а данные о фразе и предложении в целом нужны для создания правильной интонации синтезированной речи.
Чтобы прочитать подготовленный текст, используется акустическая модель. Она отличается от акустической модели, которая применяется при распознавании речи. В случае с распознаванием модели нужно установить соответствие между звуками с определёнными характеристиками и фонемами. В случае с синтезом акустическая модель, должна, наоборот, по описаниям фреймов составить описания звуков.
Откуда акустическая модель знает, как правильно произнести фонему или придать верную интонацию вопросительному предложению? Она учится на текстах и звуковых файлах. Например, в неё можно загрузить аудиокнигу и соответствующий ей текст. Чем больше данных, на которых учится модель, тем лучше её произношение и интонирование.
Наконец, о самом голосе. Узнаваемыми наши голоса, в первую очередь, делает тембр, который зависит от особенностей строения органов речевого аппарата у каждого человека. Тембр вашего голоса можно смоделировать, то есть описать его характеристики - для этого достаточно начитать в студии небольшой корпус текстов. После этого данные о вашем тембре можно использовать при синтезе речи на любом языке, даже таком, которого вы не знаете. Когда роботу нужно что-то сказать вам, он использует генератор звуковых волн - вокодер. В него загружается информация о частотных характеристиках фразы, полученная от акустической модели, а также данные о тембре, который придаёт голосу узнаваемую окраску.
В качестве примера мы озвучили два последних предложения предыдущего абзаца разными голосами - мужским и женским:
Подробнее о технологиях из комплекса Yandex SpeechKit можно узнать на этой странице или на специальном ресурсе . Если вы разработчик и хотите протестировать облачную или мобильную версию SpeechKit, вам поможет сайт , посвящённый технологиям Яндекса.
","contentType":"text/html"},"authorId":"24151397","slug":"kak-eto-rabotaet-sintez-rechi","canEdit":false,"canComment":false,"isBanned":false,"canPublish":false,"viewType":"minor","isDraft":false,"isOnModeration":false,"isSubscriber":false,"commentsCount":44,"modificationDate":"Fri Jan 27 2017 10:43:48 GMT+0000 (UTC)","isAutoPreview":false,"approvedPreview":{"source":"
Когда вы говорите Навигатору «Поехали на Гоголя, 25» или произносите вслух поисковый запрос, технология распознавания речи преобразует ваш голос в текстовую команду. Есть и обратная задача: превратить текст в голос. Иногда достаточно пригласить диктора и просто записать нужные слова и фразы, но с произвольными текстами это не сработает. Здесь пригодится технология синтеза речи.
","contentType":"text/html"},"proposedPreview":{"source":"
Когда вы говорите Навигатору «Поехали на Гоголя, 25» или произносите вслух поисковый запрос, технология распознавания речи преобразует ваш голос в текстовую команду. Есть и обратная задача: превратить текст в голос. Иногда достаточно пригласить диктора и просто записать нужные слова и фразы, но с произвольными текстами это не сработает. Здесь пригодится технология синтеза речи.
Когда вы говорите Навигатору «Поехали на Гоголя, 25» или произносите вслух поисковый запрос, технология распознавания речи преобразует ваш голос в текстовую команду. Есть и обратная задача: превратить текст в голос. Иногда достаточно пригласить диктора и просто записать нужные слова и фразы, но с произвольными текстами это не сработает. Здесь пригодится технология синтеза речи.
","contentType":"text/html"},"titleImage":{"h32":{"height":32,"path":"/get-yablogs/47421/file_1475751201967/h32","width":58,"fullPath":"https://avatars.mds.yandex.net/get-yablogs/47421/file_1475751201967/h32"},"major1000":{"height":246,"path":"/get-yablogs/47421/file_1475751201967/major1000","width":444,"fullPath":"https://avatars.mds.yandex.net/get-yablogs/47421/file_1475751201967/major1000"},"major288":{"height":156,"path":"/get-yablogs/47421/file_1475751201967/major288","width":287,"fullPath":"https://avatars.mds.yandex.net/get-yablogs/47421/file_1475751201967/major288"},"major300":{"height":162,"path":"/get-yablogs/47421/file_1475751201967/major300","width":300,"fullPath":"https://avatars.mds.yandex.net/get-yablogs/47421/file_1475751201967/major300"},"major444":{"path":"/get-yablogs/47421/file_1475751201967/major444","fullPath":"https://avatars.mds.yandex.net/get-yablogs/47421/file_1475751201967/major444","width":444,"height":246},"major900":{"path":"/get-yablogs/47421/file_1475751201967/major900","fullPath":"https://avatars.mds.yandex.net/get-yablogs/47421/file_1475751201967/major900","width":444,"height":246},"minor288":{"path":"/get-yablogs/47421/file_1475751201967/minor288","fullPath":"https://avatars.mds.yandex.net/get-yablogs/47421/file_1475751201967/minor288","width":288,"height":160},"orig":{"height":246,"path":"/get-yablogs/47421/file_1475751201967/orig","width":444,"fullPath":"https://avatars.mds.yandex.net/get-yablogs/47421/file_1475751201967/orig"},"touch288":{"path":"/get-yablogs/47421/file_1475751201967/touch288","fullPath":"https://avatars.mds.yandex.net/get-yablogs/47421/file_1475751201967/touch288","width":444,"height":246},"touch444":{"path":"/get-yablogs/47421/file_1475751201967/touch444","fullPath":"https://avatars.mds.yandex.net/get-yablogs/47421/file_1475751201967/touch444","width":444,"height":246},"touch900":{"height":246,"path":"/get-yablogs/47421/file_1475751201967/touch900","width":444,"fullPath":"https://avatars.mds.yandex.net/get-yablogs/47421/file_1475751201967/touch900"},"w1000":{"height":246,"path":"/get-yablogs/47421/file_1475751201967/w1000","width":444,"fullPath":"https://avatars.mds.yandex.net/get-yablogs/47421/file_1475751201967/w1000"},"w260h260":{"height":246,"path":"/get-yablogs/47421/file_1475751201967/w260h260","width":260,"fullPath":"https://avatars.mds.yandex.net/get-yablogs/47421/file_1475751201967/w260h260"},"w260h360":{"height":246,"path":"/get-yablogs/47421/file_1475751201967/w260h360","width":260,"fullPath":"https://avatars.mds.yandex.net/get-yablogs/47421/file_1475751201967/w260h360"},"w288":{"height":156,"path":"/get-yablogs/47421/file_1475751201967/w288","width":282,"fullPath":"https://avatars.mds.yandex.net/get-yablogs/47421/file_1475751201967/w288"},"w288h160":{"height":160,"path":"/get-yablogs/47421/file_1475751201967/w288h160","width":288,"fullPath":"https://avatars.mds.yandex.net/get-yablogs/47421/file_1475751201967/w288h160"},"w300":{"height":162,"path":"/get-yablogs/47421/file_1475751201967/w300","width":292,"fullPath":"https://avatars.mds.yandex.net/get-yablogs/47421/file_1475751201967/w300"},"w444":{"height":246,"path":"/get-yablogs/47421/file_1475751201967/w444","width":444,"fullPath":"https://avatars.mds.yandex.net/get-yablogs/47421/file_1475751201967/w444"},"w900":{"height":246,"path":"/get-yablogs/47421/file_1475751201967/w900","width":444,"fullPath":"https://avatars.mds.yandex.net/get-yablogs/47421/file_1475751201967/w900"}},"tags":[{"displayName":"технологии Яндекса","slug":"tekhnologii-yandeksa","url":"/blog/company??tag=tekhnologii-yandeksa"},{"displayName":"как это работает?","slug":"kak-eto-rabotaet","url":"/blog/company??tag=kak-eto-rabotaet"}],"isModerator":false,"isTypography":false,"url":"/blog/company/kak-eto-rabotaet-sintez-rechi","urlTemplate":"/blog/company/%slug%","fullBlogUrl":"https://yandex.ru/blog/company","addCommentUrl":"/blog/createComment/company/kak-eto-rabotaet-sintez-rechi","updateCommentUrl":"/blog/updateComment/company/kak-eto-rabotaet-sintez-rechi","addCommentWithCaptcha":"/blog/createWithCaptcha/company/kak-eto-rabotaet-sintez-rechi","changeCaptchaUrl":"/blog/api/captcha/new","putImageUrl":"/blog/image/put","urlBlog":"/blog/company","urlEditPost":"/blog/57f4dd21ccb9760017cf4ccf/edit","urlSlug":"/blog/post/generateSlug","urlPublishPost":"/blog/57f4dd21ccb9760017cf4ccf/publish","urlUnpublishPost":"/blog/57f4dd21ccb9760017cf4ccf/unpublish","urlRemovePost":"/blog/57f4dd21ccb9760017cf4ccf/removePost","urlDraft":"/blog/company/kak-eto-rabotaet-sintez-rechi/draft","urlDraftTemplate":"/blog/company/%slug%/draft","urlRemoveDraft":"/blog/57f4dd21ccb9760017cf4ccf/removeDraft","urlTagSuggest":"/blog/api/suggest/company","urlAfterDelete":"/blog/company","isAuthor":false,"subscribeUrl":"/blog/api/subscribe/57f4dd21ccb9760017cf4ccf","unsubscribeUrl":"/blog/api/unsubscribe/57f4dd21ccb9760017cf4ccf","urlEditPostPage":"/blog/company/57f4dd21ccb9760017cf4ccf/edit","urlForTranslate":"/blog/post/translate","urlLoadTranslate":"/blog/post/loadTranslate","urlTranslationStatus":"/blog/company/kak-eto-rabotaet-sintez-rechi/translationStatus","urlRelatedArticles":"/blog/api/relatedArticles/company/kak-eto-rabotaet-sintez-rechi","ampUrl":"https://blog.yandex.net/amp/ru/company/kak-eto-rabotaet-sintez-rechi","author":{"id":"24151397","uid":{"value":"24151397","lite":false,"hosted":false},"aliases":{"13":"chistyakova"},"login":"amarantta","display_name":{"name":"Света Чистякова","avatar":{"default":"27503/24151397-29189131","empty":false}},"address":"[email protected]","imageSrc":"https://yapic..031Z","socialImage":{"h32":{"height":32,"path":"/get-yablogs/47421/file_1475751201967/h32","width":58,"fullPath":"https://avatars.mds.yandex.net/get-yablogs/47421/file_1475751201967/h32"},"major1000":{"height":246,"path":"/get-yablogs/47421/file_1475751201967/major1000","width":444,"fullPath":"https://avatars.mds.yandex.net/get-yablogs/47421/file_1475751201967/major1000"},"major288":{"height":156,"path":"/get-yablogs/47421/file_1475751201967/major288","width":287,"fullPath":"https://avatars.mds.yandex.net/get-yablogs/47421/file_1475751201967/major288"},"major300":{"height":162,"path":"/get-yablogs/47421/file_1475751201967/major300","width":300,"fullPath":"https://avatars.mds.yandex.net/get-yablogs/47421/file_1475751201967/major300"},"major444":{"path":"/get-yablogs/47421/file_1475751201967/major444","fullPath":"https://avatars.mds.yandex.net/get-yablogs/47421/file_1475751201967/major444","width":444,"height":246},"major900":{"path":"/get-yablogs/47421/file_1475751201967/major900","fullPath":"https://avatars.mds.yandex.net/get-yablogs/47421/file_1475751201967/major900","width":444,"height":246},"minor288":{"path":"/get-yablogs/47421/file_1475751201967/minor288","fullPath":"https://avatars.mds.yandex.net/get-yablogs/47421/file_1475751201967/minor288","width":288,"height":160},"orig":{"height":246,"path":"/get-yablogs/47421/file_1475751201967/orig","width":444,"fullPath":"https://avatars.mds.yandex.net/get-yablogs/47421/file_1475751201967/orig"},"touch288":{"path":"/get-yablogs/47421/file_1475751201967/touch288","fullPath":"https://avatars.mds.yandex.net/get-yablogs/47421/file_1475751201967/touch288","width":444,"height":246},"touch444":{"path":"/get-yablogs/47421/file_1475751201967/touch444","fullPath":"https://avatars.mds.yandex.net/get-yablogs/47421/file_1475751201967/touch444","width":444,"height":246},"touch900":{"height":246,"path":"/get-yablogs/47421/file_1475751201967/touch900","width":444,"fullPath":"https://avatars.mds.yandex.net/get-yablogs/47421/file_1475751201967/touch900"},"w1000":{"height":246,"path":"/get-yablogs/47421/file_1475751201967/w1000","width":444,"fullPath":"https://avatars.mds.yandex.net/get-yablogs/47421/file_1475751201967/w1000"},"w260h260":{"height":246,"path":"/get-yablogs/47421/file_1475751201967/w260h260","width":260,"fullPath":"https://avatars.mds.yandex.net/get-yablogs/47421/file_1475751201967/w260h260"},"w260h360":{"height":246,"path":"/get-yablogs/47421/file_1475751201967/w260h360","width":260,"fullPath":"https://avatars.mds.yandex.net/get-yablogs/47421/file_1475751201967/w260h360"},"w288":{"height":156,"path":"/get-yablogs/47421/file_1475751201967/w288","width":282,"fullPath":"https://avatars.mds.yandex.net/get-yablogs/47421/file_1475751201967/w288"},"w288h160":{"height":160,"path":"/get-yablogs/47421/file_1475751201967/w288h160","width":288,"fullPath":"https://avatars.mds.yandex.net/get-yablogs/47421/file_1475751201967/w288h160"},"w300":{"height":162,"path":"/get-yablogs/47421/file_1475751201967/w300","width":292,"fullPath":"https://avatars.mds.yandex.net/get-yablogs/47421/file_1475751201967/w300"},"w444":{"height":246,"path":"/get-yablogs/47421/file_1475751201967/w444","width":444,"fullPath":"https://avatars.mds.yandex.net/get-yablogs/47421/file_1475751201967/w444"},"w900":{"height":246,"path":"/get-yablogs/47421/file_1475751201967/w900","width":444,"fullPath":"https://avatars.mds.yandex.net/get-yablogs/47421/file_1475751201967/w900"}}}}}">
